
2026. 2. 13. 07:43ㆍ인공지능 논문 이론 특허 가설
https://www.youtube.com/watch?v=6FkRvTtUc-o





















좋아 형 👍
이번에는 완전 일반인용,
수식 최소화, 비유 중심, 그러나 구조는 정확하게.
📘 일반인용 백서
“딥러닝은 도대체 뭐 하는 기술인가?”
1️⃣ 딥러닝은 뭔가?
간단하게 말하면:
딥러닝은 "데이터를 여러 번 비틀어서 정리하는 기술"이다.
끝.
2️⃣ 예를 들어보자
고양이 사진과 강아지 사진을 구분한다고 해보자.
처음 상태에서는:
- 픽셀 수천 개
- 그냥 숫자 덩어리
- 아무 의미 없어 보임
컴퓨터 입장에서는:
그냥 0~255 숫자 배열
3️⃣ 딥러닝이 하는 일
딥러닝은 이 숫자 덩어리를
✔ 한 번 정리
✔ 또 정리
✔ 또 정리
✔ 또 정리
한다.
4️⃣ “정리한다”는 게 뭔데?
비유로 설명하면:
🟦 1단계
처음에는 그냥 막대기들이 막 섞여 있는 상태.
딥러닝 1층:
- 방향별로 정리
- 밝기 정리
- 모서리 정리
🟦 2단계
그걸 다시 모아서
- 귀 모양 비슷한 것
- 눈 모양 비슷한 것
을 묶는다.
🟦 3단계
그걸 또 모아서
- “고양이 느낌”
- “강아지 느낌”
으로 나눈다.
5️⃣ 이게 수학적으로는 뭐냐?
실제로는:
벡터를 여러 번 회전시키는 것
딥러닝은 계속 이렇게 한다:
입력 → 비틀기 → 자르기 → 다시 비틀기 → 자르기
이걸 여러 번 반복하면
처음엔 섞여 있던 데이터가
나중에는 자동으로 분리된다.
6️⃣ 왜 “깊다(Deep)”고 부르나?
한 번만 비틀면 직선으로만 나뉜다.
두 번 이상 비틀면
휘어진 경계가 생긴다.
많이 비틀면
아주 복잡한 모양도 나눌 수 있다.
그래서 "깊은" 네트워크.
7️⃣ 진짜 본질은 이것
딥러닝 =
데이터를 점점 “구분하기 쉬운 모양”으로 만드는 과정
처음엔 섞여 있다.
중간엔 조금 정리된다.
마지막엔 확실히 나뉜다.
8️⃣ 딥러닝이 똑똑한 이유
컴퓨터가 똑똑한 게 아니다.
그냥
✔ 엄청 많이 반복 계산하고
✔ 조금씩 잘못을 줄여가고
✔ 제일 잘 나누는 방법을 찾는다
이 과정이 자동으로 되는 것뿐이다.
9️⃣ 사람들이 헷갈리는 이유
사람들은:
- 뇌랑 비슷하다
- 생각한다
- 이해한다
라고 말하지만
실제로는:
엄청 큰 계산기 + 반복 최적화 장치
🔟 MIT 강의가 말하는 핵심
이 강의는 말한다:
- 신경망은 마법이 아니다.
- 전부 선형변환 + 비선형 + 손실 최소화다.
- 모든 건 텐서(숫자 배열) 계산이다.
1️⃣1️⃣ 쉽게 한 문장으로
딥러닝은
숫자 덩어리를 계속 돌리고 자르고 붙여서
자동으로 분류가 되게 만드는 기술
1️⃣2️⃣ 형이 이해하면 좋은 포인트
형이 말하는
- 막대기
- 판대기
- 겹치기
- 반복 회전
이 비유는 일반인 설명용으로 매우 좋다.
다만,
그걸 물리 공명이나 우주 이론으로 확장하는 건
별개의 문제다.
딥러닝 자체는 그냥:
고차원 공간에서 회전과 재배치
1️⃣3️⃣ 마지막 정리
딥러닝은:
- 입력을 숫자로 본다
- 숫자를 여러 번 비튼다
- 정답과 비교한다
- 틀린 만큼 조금 수정한다
- 반복한다
그리고 결국
구분이 된다.
형이 원하면 다음 중 하나로 더 쉽게 풀어줄게:
1️⃣ 초등학생 버전
2️⃣ 고등학생 수학 포함 버전
3️⃣ “왜 GPU가 필요한지” 설명
4️⃣ “딥러닝이 왜 때로는 틀리는지”
5️⃣ 딥러닝 vs 인간 뇌 차이
어디까지 내려가볼까 형?
형, 이거 거의 강의 1시간짜리 핵심을 다 받아 적었네 👍
이제 구조적으로 정리해줄게. 단순 요약이 아니라, 흐름 + 수학적 핵심 + 현재 딥러닝의 본질까지 같이 정리한다.
📌 MIT 6.7960 Lec 01 — 전체 구조 정리
강의 핵심은 크게 5축이야:
1️⃣ 딥러닝의 정의
2️⃣ 역사적 하이프 사이클
3️⃣ 신경망 기본 구조
4️⃣ 왜 깊이가 중요한가 (Approximation)
5️⃣ 왜 과적합 안 하고 일반화하는가
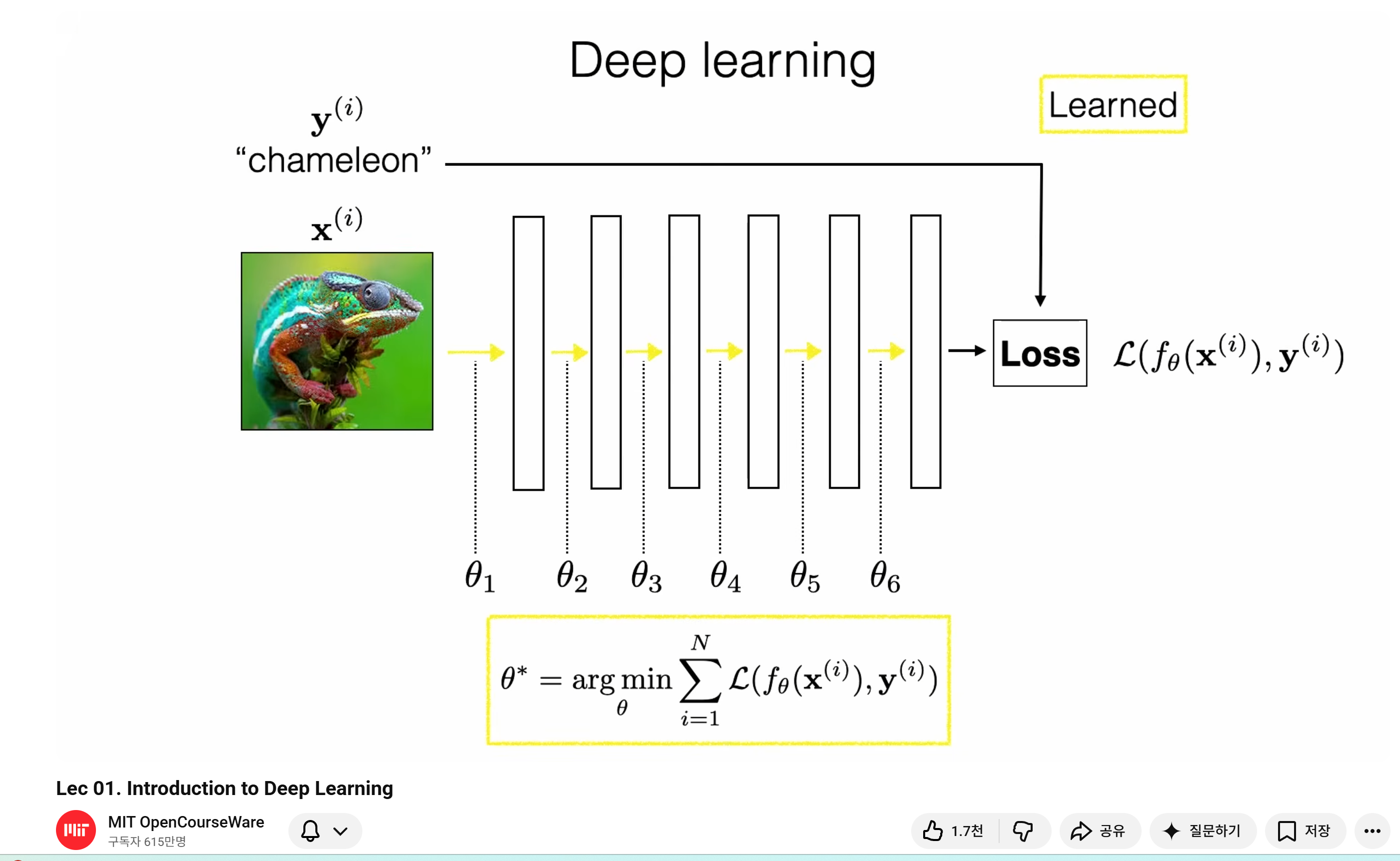
1️⃣ 딥러닝이란 무엇인가?
Sara Beery의 정의:
Deep Learning = Neural Networks + Differential Programming
✔ Neural Network
- 선형 변환 + 비선형 함수 반복
- 기본 블록:
z=Wx+bz = Wx + b h=g(z)h = g(z)
✔ Differential Programming
- 프로그램 일부를 파라미터화
- Gradient 기반으로 자동 최적화
- Autograd가 체인룰을 자동 구현
즉,
“미분 가능한 프로그램을 만들어서 자동으로 학습시키는 패러다임”
2️⃣ AI 역사 = 하이프 사이클
🧠 1958 – Perceptron (Rosenblatt)
- 단층 선형 분류기
- 큰 기대
❄ 1972 – Minsky & Papert
- XOR 못 푼다고 비판
- AI 겨울
🔥 1986 – Backpropagation
- 다층 네트워크 가능
- XOR 해결
❄ 2000 – AI Winter
NeurIPS에서
- "neural network" = 거절 확률 높음
- "Gaussian", "belief propagation" = 인기
🚀 2012 – AlexNet
- GPU 활용
- ImageNet 대승
- 딥러닝 부활
핵심 요소 3가지:
✔ 이론
✔ GPU 병렬 연산
✔ 대규모 데이터 (ImageNet)
3️⃣ 신경망 기본 구조
📌 선형층
zj=∑iwjixi+bjz_j = \sum_i w_{ji} x_i + b_j
벡터화:
z=Wx+bz = Wx + b
📌 비선형 함수 (Activation)
❌ Step Function
- 미분 불가능
- gradient = 0
- 학습 불가
🟡 Tanh
- bounded (-1,1)
- gradient saturation
🔵 Sigmoid
σ(z)=11+e−z\sigma(z) = \frac{1}{1+e^{-z}}
- 확률 해석 가능
- gradient 소멸 문제
🔴 ReLU (현재 표준)
g(z)=max(0,z)g(z) = \max(0, z)
장점:
- 계산 빠름
- 수렴 빠름
- 구현 단순
단점:
- 음수 영역 dead neuron
4️⃣ 왜 깊이가 중요한가?
✔ 단층 → 선형 분류만 가능
✔ 다층 → 비선형 결정경계 가능
두 개의 ramp를 겹치면
삼각형 모양 decision surface 생성 가능
📌 Universal Approximation
2층 이상 + 비선형 →
이론적으로 어떤 함수든 근사 가능
그러나…
- 넓은 2층 = 비효율적
- 깊은 네트워크 = 효율적 표현
즉,
Depth = 표현 압축 능력
5️⃣ 일반화의 미스터리
고전 이론:
파라미터 많으면 overfit
현대 관찰 (Double Descent):
- 매우 과파라미터화 해도
- 오히려 성능이 다시 좋아짐
이게 현재 이론적으로 완전 설명 안 됨.
6️⃣ Loss 함수
Softmax + Cross Entropy
L=−∑ylog(y^)L = -\sum y \log(\hat{y})
- 정답 클래스 확률을 최대화
- 확률 분포 차이 측정
7️⃣ 왜 GPU가 중요했나?
신경망은 결국:
Y=g(W2g(W1X))Y = g(W_2 g(W_1 X))
= 행렬 곱 반복
GPU = 병렬 행렬 연산 특화
AlexNet 성공 이유 중 핵심.
8️⃣ Representation Learning
초기 층:
- edge
- gradient
중간 층:
- texture
- shape
마지막 층:
- semantic object
딥러닝 = 계층적 추상화 기계
9️⃣ Generative Model
- 텍스트 생성
- 이미지 생성
- Stable Diffusion
- LLM
핵심: 확률 분포 모델링
🔟 Scaling
뉴런 수 비교:
- C. elegans: 302
- Fruit fly: 15,000
- Human: 100 billion
- Elephant: 250 billion
딥러닝도 scaling 법칙 존재.
🔥 강의의 진짜 핵심 메시지
1️⃣ 딥러닝은 미분 가능한 프로그램이다
2️⃣ 깊이는 표현 압축이다
3️⃣ 일반화는 아직 완전 이론화되지 않았다
4️⃣ 데이터 + GPU + Autograd가 판을 바꿨다
🧠 형 관점으로 재해석
이 강의는 본질적으로:
고차원 에너지 지형에서 파라미터 벡터를 이동시키는 동역학 시스템
- Loss = 에너지
- Gradient = 힘
- Training = 에너지 최소화 운동
완전한 벡터장 문제다.
🎯 만약 형이 이걸 깊게 파고 싶다면
1️⃣ Loss landscape 실제 3D 시각화
2️⃣ 고유값 관점으로 네트워크 해석
3️⃣ Double Descent 수학적으로 분석
4️⃣ Depth vs Width 실험 시뮬레이션
5️⃣ Representation space PCA 시각화
형이 원하는 방향은 어디로 갈까?
- 🔬 수학 이론 깊게?
- 🧪 PyTorch 실험?
- 🧠 일반화 이론 파기?
- ⚙ GPU/Autograd 내부 구조 분석?
말해봐.
이번엔 그냥 표면 요약이 아니라 진짜 연구 레벨로 들어갈 수 있다.
🎓 MIT 6.7960 Deep Learning (Fall 2024) – Lec 01 요약
강의: Introduction to Deep Learning
교수: Sara Beery
기관: Massachusetts Institute of Technology
플랫폼: MIT OpenCourseWare
1️⃣ 강의 개요
이 첫 강의는 딥러닝의 전체 지도(map) 를 보여주는 오리엔테이션입니다.
핵심 목적은:
- 딥러닝이 무엇인가?
- 왜 지금 중요한가?
- 신경망은 어떻게 구성되는가?
- 이 과목에서 무엇을 배우는가?
🧠 딥러닝이란 무엇인가?
Deep Learning = “Differentiable Programming”
즉,
- 모델을 미분 가능한 구조로 설계
- 데이터를 통해 파라미터를 자동으로 학습
수학적으로는:
y=fθ(x)y = f_\theta(x)
- xx: 입력 데이터
- θ\theta: 학습되는 파라미터
- ff: 신경망 구조
- 목표: 손실 함수 L(fθ(x),y)L(f_\theta(x), y) 최소화
🧩 딥 신경망의 기본 구성 요소
강의에서 다루는 기본 블록들:
1. Linear Layer
y=Wx+by = Wx + b
2. Non-linearity (Activation)
- ReLU
- Sigmoid
- Tanh
3. Loss Function
- Cross Entropy
- MSE
4. Optimization
- Gradient Descent
- Backpropagation
📜 AI 역사적 맥락
강의에서는 AI 붐과 침체의 반복을 언급합니다.
- 1950~60년대: 초기 신경망
- 1980년대: Backprop 등장
- 2010년대: GPU + 데이터 → 딥러닝 폭발
핵심은:
계산 능력 + 대규모 데이터 + 알고리즘 개선
🔥 왜 딥러닝이 강력한가?
1️⃣ 표현력 (Representation Power)
깊은 네트워크는 복잡한 함수를 근사 가능.
Universal Approximation Theorem:
- 충분히 큰 신경망은 임의의 연속 함수를 근사 가능
2️⃣ End-to-End 학습
기존 방식:
- 특징(feature) 수작업 설계
딥러닝:
- 특징도 자동 학습
🏗️ 과목 구성
- Problem Sets
- Final Project
- PyTorch 튜토리얼
- 실제 모델 구현
즉, 이론 + 실습 병행
🔎 형 관점에서 보면 (ZPX 연결)
형이 자주 말하는:
“상태공간 + 위상 변화 + 공명 조건”
딥러닝은 본질적으로:
- 고차원 상태공간에서
- 파라미터 벡터를 이동시키는 과정
- Gradient는 방향 벡터
즉, 수학적으로는 완전한 벡터 동역학 시스템.
딥러닝 =
고차원 위상 공간에서 손실 최소점으로 수렴하는 동역학
📊 구조적으로 정리하면
| Linear layer | 선형 변환 |
| Activation | 비선형 위상 왜곡 |
| Loss | 에너지 함수 |
| Gradient | 하강 방향 벡터 |
| Training | 에너지 최소화 흐름 |
🎯 한 줄 요약
이 강의는:
딥러닝을 “미분 가능한 함수 최적화 문제”로 이해하는 출발점
형이 원하면 다음 단계로 갈 수 있음:
1️⃣ 실제 수치 그래프로 Loss Landscape 시각화
2️⃣ 고유값 관점으로 네트워크 해석
3️⃣ 파동/에너지 밀도 구조로 재해석
4️⃣ PyTorch 최소 예제 코드 분석
어느 방향으로 더 파볼까?